Version 4.0
Wichtige Hinweise
Der RenderServer benötigt das .NET-Framework 4.5 oder höher. Wenn es nicht installiert ist, wird die Einrichtung des RenderServers automatisch übersprungen.
Datentabellen mit CSV-Import
Datentabellen sind einfache tabellarische Datenlisten, deren Inhalt verwendet werden kann, um Vorschläge für ein Archiv-Datenfeld anzubieten. Sie stellen in dem Fall eine zusätzliche Quelle für Vorschläge dar neben den bereits existierenden Quellen wie eigene Werte, existierende Werte und externe Quelle.
Datentabellen werden in der Administrations-Oberfläche im Bereich Datentabellen konfiguriert. Die Definition der Datenfelder einer Tabelle erfolgt auf die gleiche Weise wie die Grundkonfiguration der Spalten eines Archivs.
Das Befüllen der Tabelle mit Daten erfolgt an der gleichen Stelle über den Button Daten anzeigen. Es besteht die Möglichkeit, einzelne Datensätze anzulegen, zu bearbeiten, zu löschen oder aus einer CSV-Datei zu importieren.
Der Batch-Import von großen Datenmengen aus einer CSV-Datei kann über den Button Import in der Datenansicht einer Datentabelle gestartet werden. Zunächst muss eine CSV-Datei hochgeladen werden, anschließend muss man die Import-Optionen wie Feld-Trennzeichen etc. auf die hochgeladene CSV-Datei anpassen.
Bei jeder Änderung der Import-Optionen bekommt man eine sofortige Vorschau angezeigt, wie die ersten 1000 Zeilen der CSV-Datei importiert werden würden. Somit kann man schnell beurteilen, ob die Daten korrekt importiert werden. Bei Validierungfehlern wird die Tabellenzelle rot umrandet.
Im folgenden Beispiel wurde das Feld-Trennzeichen falsch ausgewählt, sodass alle Daten in der ersten Spalte landen würden, was man anhand der Vorschau schnell erkennen kann:
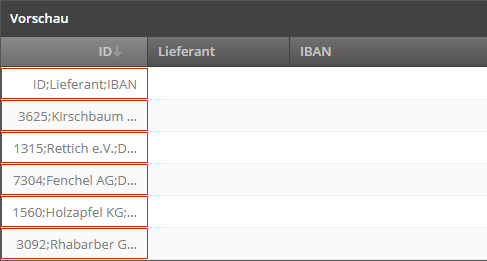
Im nächsten Schritt wird nun das richtige Feld-Trennzeichen ausgewählt:
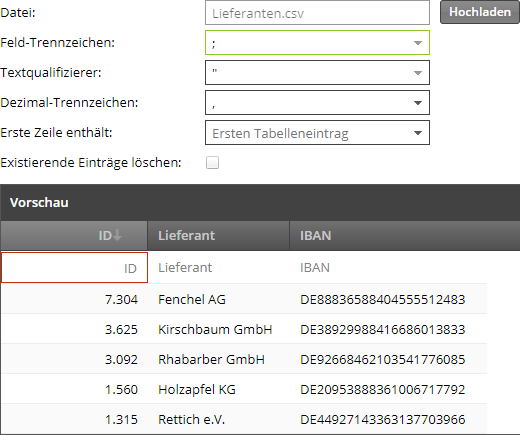
Jetzt passt bereits fast alles, nur in der ersten Zeile wird noch ein Fehler angezeigt. Anhand der Option “Erste Zeile enthält” kann eingestellt werden, wie die Spaltenzuordnung von der CSV-Datei zur Datentabelle aussieht. Es gibt folgende drei Optionen:
- Ersten Tabelleneintrag
Hier wird angenommen, dass die Reihenfolge der Spalten in der CSV-Datei genau so ist wie in der Datentabelle.
- Spalten-Kurznamen
In der ersten Zeile der CSV-Datei steht der entsprechende Kurzname des Feldes in der Datentabelle, in das die Werte importiert werden. Wenn die Spalte der CSV einen nicht existierenden Kurznamen enthält, wird diese Spalte beim Import ignoriert.
- Spalten-Namen
Identisch zu Spalten-Kurznamen, nur dass der Anzeigename des Datenfeldes verwendet wird.
Im Beispiel steht in der ersten Zeile der Spalten-Name, wenn hier also diese Einstellung gewählt ist, wird kein Fehler mehr angezeigt:
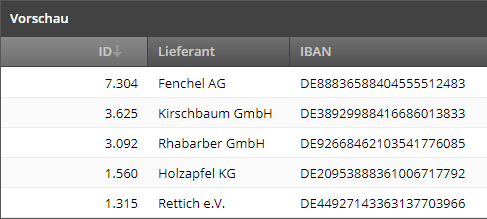
Mit der Option Existierende Einträge löschen werden vor dem Import alte Werte aus der Datentabelle gelöscht. Das ist beispielsweise dann sinnvoll, wenn man eine sich regelmäßig ändernde CSV-Datei immer wieder vollständig importieren möchte, ohne dass man dann anschließend alte Werte doppelt in der Datentabelle sieht.
Um die Einträge einer Datentabelle als Vorschläge für ein Archiv-Datenfeld zu verwenden, wird die Datentabelle in den erweiterten Optionen der Spalte als Vorschlagsquelle definiert. Wählt man hier unter Vorschläge den Eintrag Datentabelle aus, kann man anschließend eine Spalte einer Datentabelle auswählen, aus der die Vorschläge bezogen werden sollen.
Verbesserte SmartIndexing-Regeln mit Vorschlägen aus Datentabellen
Für Rechnungen gibt es nun deutlich verbesserte, mitgelieferte SmartIndexing-Regeln:
IBANs werden validiert, d. h. es werden nur noch gültige IBANs vorgeschlagen.
Die Trefferquote für Beträge wie Bruttobetrag, Nettobetrag und Steuerbetrag ist mit einem neuen Verfahren deutlich höher.
Die beiden neuen Regeln Lieferant und Kreditor ermitteln Werte durch Nachschlagen in einer Datentabelle anhand der IBAN. Dafür wird in dieser Version automatisch eine erste Datentabelle mit dem Namen Lieferanten eingerichtet, die die drei Spalten IBAN, Name und Fibu-Konto enthält und von den beiden SmartIndexing-Regeln Lieferant und Kreditor verwendet wird. Dazu muss man diese Datentabelle zunächst mit Daten aus einer CSV-Datei füllen, anschließend arbeiten diese Regeln folgendermaßen:
Wenn die SmartIndexing-Regel Lieferant ausgewählt wird, wird zunächst eine IBAN aus dem Dokument extrahiert. Falls das erfolgreich ist, wird in der Datentabelle nachgesehen, welcher Name zu dieser IBAN gehört. Falls ein Wert gefunden ist, wird dieser Name von SmartIndexing zurückgegeben.
Die Regel Kreditor funktioniert identisch, nur dass die Datentabellen-Spalte Fibu-Konto zu der gefundenen IBAN zurückgegeben wird.
Alle neuen SmartIndexing-Regeln sind im Abschnitt Eingangsrechnungen zu finden.
Zwei-Faktor-Authentifizierung
Neben der herkömmlichen Anmeldung nur mit einem Passwort kann nun auch die Zwei-Faktor-Authentifizierung (2FA) genutzt werden. In docs365 documents wird neben dem Passwort ein Zahlencode verwendet, der für jede Anmeldung neu generiert wird.
Die 2FA wird für jeden User einzeln über die User-Einstellungen in der Administrations-Oberfläche aktiviert. Nach dem Aktivieren finden Sie dort einen Button Info, über den Sie eine detaillierte Anleitung zur weiteren Einrichtung und Verwendung der 2FA erhalten.
Neue Gestaltung der Administrations-Oberfläche
Bislang wurden das Datengitter und der aktuell bearbeitete Eintrag in der Administrations-Oberfläche immer nebeneinander angezeigt, was auf kleineren Bildschirmen manchmal etwas problematisch sein konnte.
Ab sofort wird in der Administrations-Oberfläche zunächst nur das Datengitter angezeigt, mit dem man eine gute Übersicht über alle Daten bekommt. Wenn man einen Eintrag bearbeiten möchte, muss man diesen auswählen und auf Bearbeiten klicken oder alternativ einen Doppelklick durchführen.
Das Formular zum Bearbeiten wird dann anschließend anstelle des Datengitters angezeigt. Durch einen Klick auf Zurück in der oberen Titelzeile gelangt man zurück zum Datengitter, mit den beiden Pfeil-Buttons daneben kann man zum vorherigen bzw. nächsten Datensatz springen.
Die Reiter z. B. in der Archivkonfiguration wurden entfernt, alle Optionen sind jetzt übereinander in verschiedenen Abschnitten auf einer einzelnen Seite zu sehen.
RenderServer für Office-Dokumente
In Version 3.0.14 wurde bereits Unterstützung für den neuen RenderServer zum Erzeugen von Vorschau-PDFs aus Office-Dokumenten eingebaut. Ab Version 4.0 wird der RenderServer standardmäßig mit installiert und aktiviert. Es wird das Konvertieren von Word- und Excel-Dokumenten unterstützt.
Über die Datei RenderServer.ini im config-Verzeichnis der Installation kann der RenderServer
konfiguriert werden. Am wichtigsten ist hierbei die Option Converter in der Sektion
[Office], die einstellt, mit welchem Verfahren die Office-Dokumente konvertiert werden sollen.
Die Konverter DevExpress und EVO basieren auf mitgelieferten Bibliotheken und sind daher
immer verfügbar. Erfahrungsgemäß liefert DevExpress etwas bessere Ergebnisse und ist daher
voreingestellt.
Der Konverter LibreOffice ruft ein installiertes LibreOffice auf, um die Office-Datei nach PDF
zu konvertieren. Da LibreOffice selbst nicht mitgeliefert wird, muss es zunächst manuell installiert
werden, außerdem muss in der Option LibreOfficePath der Pfad zur Datei soffice.exe im
Installationsverzeichnis von LibreOffice eingetragen werden:
Converter=LibreOffice
LibreOfficePath=C:\Program Files\LibreOffice\program\soffice.exe
Der Konverter MSOffice verwendet ein installiertes Microsoft Office und liefert daher
normalerweise die besten Ergebnisse. Durch eine Einschränkung von Microsoft Office selbst
funktioniert diese Methode jedoch nur, wenn man den RenderServer von einem angemeldeten Benutzer aus
aufruft, als Dienst kann man den RenderServer in diesem Fall also nicht starten.
Rate-Limiting für fehlgeschlagene Anmeldeversuche
Immer wenn ein Anmeldeversuch fehlschlägt oder ein Code für die Zwei-Faktor-Authentifizierung falsch ist, wird die IP-Adresse der Anfrage temporär in der Datenbank geloggt. Wenn es innerhalb der letzten Minute von der gleichen IP-Adresse oder aus ähnlichen Subnetzen zu viele fehlerhafte Versuche gegeben hat, werden alle weiteren Login-Versuche abgelehnt, sodass man bis zu einer Minute warten muss, bis eine Anmeldung wieder erlaubt ist. Wenn das Rate-Limiting für fehlgeschlagene Anmeldeversuche überschritten ist, wird eine entsprechende Fehlermeldung mit dem HTTP-Status-Code 429 (Too Many Requests) ausgegeben.
Damit man das Rate-Limiting nicht einfach durch den Wechsel der IP-Adresse umgehen kann (was insbesondere für IPv6 wichtig ist), werden auch ähnliche Subnetze beachtet.
Bei IPv4 werden für jedes Minuten-Intervall folgende Limits für fehlgeschlagene Anmeldeversuche erzwungen:
20 von der gleichen IP-Adresse.
200 aus dem gleichen /24-Subnetz.
2000 aus dem gleichen /20-Subnetz.
Bei IPv6 sind die Limits pro Minute wie folgt:
20 von der gleichen IP-Adresse.
200 aus dem gleichen /64-Subnetz.
400 aus dem gleichen /56-Subnetz.
1000 aus dem gleichen /48-Subnetz.
2000 aus dem gleichen /32-Subnetz.
Fehlgeschlagene Anmeldeversuche, die länger als eine Minute her sind, werden regelmäßig wieder aus der Datenbank gelöscht.
Containerformat für Speicher
Bei den Ablageorten in den Speichern ist der neue Typ Container hinzugekommen:
Im Gegensatz zum Ablageort Dateibaum (ehemals filetree genannt) speichert dieser Ablageort die Dokumente und Metadaten der Vorgänge nicht in einzelnen Dateien ab, sondern fasst die neu hinzugekommenen Dokumente gemeinsam in größere Container-Dateien zusammen. Diese Vorgehensweise hat folgende Vorteile:
Dateibasierte Backup-Programme sind bei sehr vielen kleinen Dateien oft langsam, sodass auch inkrementelle Backups sehr lange dauern können. Da die Container-Dateien von der Anzahl deutlich weniger und dazu auch noch unveränderlich sind, werden effiziente Backups deutlich vereinfacht.
Sofern keine Verschlüsselung gewünscht ist, können die archivierten Daten komprimiert werden.
Container-Speicher haben eine bessere Untersützung für WORMs.

Die Daten von neuen Archivierung werden im data-Unterverzeichnis containers zunächst
gesammelt und dann regelmäßig nach konfigurierbaren Regeln in das im Ablageort konfigurierte
Verzeichnis zusammengefügt. Ab diesem Zeitpunkt werden die einzelnen Containerdateien nicht mehr
verändert, sodass sie auch auf einem WORM abgespeichert werden können.
Das Zusammenfügen der Containerdateien wird entweder in regelmäßigen Zeitabständen gemacht oder sobald sich eine gewisse Größe an Daten angesammelt hat, je nachdem was zuerst erreicht wird:
Das Zeitintervall (Containerintervall) wird in Stunden angegeben, erlaubt sind Werte zwischen 1 und 24.
Die maximale Containergröße wird in MB angegeben, erlaubt sind Werte zwischen 1 und 1024.
Die tatsächliche Größe der erzeugen Container kann bei Verwendung von Komprimierung kleiner sein als die eingestellte maximale Containergröße, da hier die Größe der unkomprimierten Daten beachtet wird.
Für die Datenverarbeitung kann entweder Komprimierung oder Verschlüsselung eingestellt werden. Beides kann nicht kombiniert werden, da verschlüsselte Daten nicht komprimiert werden können.
Indexing-Services
SmartIndexing kann jetzt durch eigene, in Python programmierte Regeln erweitert werden, womit auch komplexe Information aus Dokumenten extrahiert und dem Benutzer vorgeschlagen wird.
Die Details der Indexing-Services werden in einer separaten Dokumentation beschrieben.
Manuelle Sortierung von Archiven
Standardmäßig werden Archive bei der Anzeige in der Oberfläche (z. B. im Viewer oder in SmartSearch) nach Namen sortiert. Diese Reihenfolge kann durch das Zahlenfeld Sortierindex in Archiven, gefilterten Archiven und zusammengefassten Archiven überschrieben werden. Es kann eine Zahl im Bereich von -9999 bis 9999 eingegeben werden.
In der Oberfläche werden die Archive nun zunächst aufgesteigend nach dem Sortierindex und bei gleichen Zahlenwerten weiterhin nach Namen sortiert. Voreingestellt ist für alle Archive der Sortierindex 0, sodass standardmäßig weiterhin die Sortierung nach Namen eingestellt ist.
Gruppeneingang
Ab sofort ist es möglich, Dokumente im Eingang innerhalb einer Gruppe zu teilen. Dazu wird ein Dokument aus dem Eingang eines Benutzers an eine Gruppe weitergeleitet und ist von da an im Eingang aller Mitglieder der Gruppe zu sehen, so dass es von jedem dieser Mitglieder archiviert oder weitergeleitet werden kann.
Gruppen werden in der Administrations-Oberfläche im Bereich Gruppen definiert. Einer Gruppe können beliebig viele Benutzer zugeordnet werden. Andersherum kann ein Benutzer in seinen Einstellungen einer oder mehreren Gruppen zugeordnet werden.
Für jede Gruppe kann eine Farbe eingestellt werden, sodass im Eingang leichter unterschieden werden kann, über welchen Gruppeneingang man das Dokument im Eingang sieht.
Um ein Dokument aus dem Eingang einer Gruppe verfügbar zu machen, wird der Button Weiterleiten verwendet. Während an dieser Stelle bisher nur an einen einzelnen Benutzer weitergeleitet werden konnte, kann hier nun auch eine Gruppe ausgewählt werden. Das Dokument erscheint dann im Eingang aller Mitglieder dieser Gruppe mit einer entsprechenden Markierung in der Spalte Gruppe. Ist der weiterleitende Benutzer selbst Teil der Gruppe, bleibt das Dokument auch im eigenen Eingang sichtbar, nun ergänzt um die Gruppen-Markierung. Andernfalls verschwindet es aus seinem Eingang, so wie sonst auch im Falle einer Weiterleitung.
Auch Hotfolder können Dokumente direkt in einem Gruppeneingang ablegen. Analog zur bisherigen Syntax
archiv@benutzer (legt das Dokument in den Eingang des Benutzers mit dem Anmeldenamen
benutzer und setzt das Archiv mit dem Kurznamen archiv als Voreinstellung) wird das Dokument
bei #Gruppenname in die Gruppe mit den Namen Gruppenname gelegt. Auch hier kann ein Archiv
über den Kurznamen vor dem # voreingestellt werden.
Verschiedenes
Wenn es beim Archivieren einen Eingabefehler in einem Datenfeld gibt, das sich nicht im sichtbaren Bereich befindet, wird automatisch zum rot umrandeten Feld gescrollt.
Der Kurzname eines gefilterten Archivs kann jetzt auch nachträglich noch verändert werden.
Wenn in einem Import-Service ein bereits existierender Vorgang bearbeitet wird, können über
result.metadatanun auch die Spaltenwerte bearbeitet werden.Wenn ein RenderServer für Office-Dokumente konfiguriert ist, wird die PDF-Vorschau nun auch für im Eingang hochgeladene Dokumente ausgeführt.
Die Oberfläche erlaubt nun auch, Vorgänge ohne angehängte Dokumente zu archivieren.
Im Vorgangsdialog wurde der Bereich Daten in einen Reiter unter dem Titel Info verschoben, so dass er nur bei Bedarf angezeigt wird. Um die Anzahl der Reiter zu reduzieren, ist der Inhalt des Reiters Historie ebenfalls in den Reiter Info verlagert worden.
Das für ein Datenfeld eingestellte Format (z. B. bei Zahlen) wird nun auch bei der Verschlagwortung im Archivieren-Dialog verwendet.
Beim Multiedit wird nun eine Fortschrittsleiste angezeigt.
Fehlerbehebungen
Im CSV-Hotfolder wurde beim Einlesen der CSV-Datei ausschließlich das Standard-Encoding des Betriebssystems (unter Windows meistens CP-1252) verwendet. Das konnte bei der Verwendung von UTF-8 zu falsch interpretierten Zeichen führen. Ab sofort werden sowohl UTF-8 (mit oder ohne Byte Order Mark) als auch ISO 8859-1 (bzw. CP-1252) unterstützt und der richtige Zeichensatz wird automatisch erkannt. Die beim Import geschriebenen CSV-Dateien im
Completed- undFailed-Verzeichnis verwenden grundsätzlich UTF-8 mit Byte Order Mark, da in diesem Format das Encoding auch von Excel immer richtig interpretiert wird.Anzeigefehler bei der Verwendung des Suchbaums mit Ja/Nein-Feldern behoben.
Wenn in einem Customisation-Skript ein
print()von bestimmten Unicode-Zeichen ausgeführt wurde, konnte es zu einer Exception kommen.