Version 1.4.0
Eingang zum Sammeln von Dokumenten
Im Tab “Aufgaben” des Webclients gibt es nun zusätzlich zum Postfach noch einen Eingang zum Sammeln von Dokumenten, die erst in einem späteren Schritt archiviert werden sollen. Dokumente können aus verschiedenen Quellen in den Eingang hochgeladen werden:
Direkt im Webclient über Drag&Drop. Dazu muss eine Datei in das Datengitter des Eingangs gezogen werden.
Der SmartClient legt Dokumente ebenfalls im Eingang ab.
Neuere Versionen von PHOENIX Capture können gescannte Dokumente direkt im Eingang ablegen.
Im Datengitter des Eingang wird die Quelle angezeigt, aus der ein Dokument importiert wurde. Solange es sich noch im Eingang befindet, ist ein Dokument noch nicht revisionssicher archiviert. Mit einem Doppelklick auf den Eintrag im Gitter oder einen Klick auf Archivieren kann das Dokument dann anschließend in einem Archiv revisionssicher abgelegt werden.
Neue Verwaltung von Speichern
Die Oberfläche, mit der Speicher und ihre Ablageorte verwaltet werden können, wurde in dieser Version grundlegend überarbeitet.
Aber auch die Verwendung der Ablageorte innerhalb der Speicher wurde in dieser Version angepasst. Bislang war es so, dass beim Hinzufügen eines neuen Ablageorts in einem Speicher nur alle neuen Vorgänge ebenfalls in diesen Ablageort geschrieben wurden. Damit hatten verschiedene Pfade u.U. einen unterschiedlichen Satz an Daten.
Wenn in einem Speicher nun mehrere Ablageorte konfiguriert sind, werden sämliche Daten in allen Ablageorten parallel abgespeichert, beispielsweise um durch Redundanz eine höhere Datensicherheit zu gewährleisten. Dieses Schema ist vergleichbar mit einem RAID-1 bei Festplatten.
Daher müssen beim Hinzufügen eines neuen Ablageort zuerst alle Daten dorthin migriert werden, bevor dieser ebenfalls benutzt werden kann. Dieser Migrationsprozess wird zuverlässig im Hintergrund durchgeführt. Während dieser Migration ist der neue Ablageort für sonstige Bearbeitung gesperrt.
Neue Speicher anlegen
Wenn man im Bereich Speicher in der Administrations-Oberfläche auf Neu klickt, wird ein Dialog geöffnet, indem man sowohl den Speicher als auch den ersten darin enthaltenen Ablageort konfiguriert. Der Ablageort wird mit sinnvollen Werten vorbelegt, sodass die Eingabe des Speichernamens grundsätzlich ausreicht.
Neuen Ablageort anlegen
Wenn ein neuer Ablageort hinzugefügt wird, werden alle Daten aus einem anderen Ablageort dorthin kopiert, sodass es anschließend zwei Kopien sämtlicher Daten gibt. Der Fortschritt dieser Datenmigration wird im Datengitter der Ablageorte angezeigt.
Ablösen von Ablageorten
Angenommen, ein Ablageort ist auf Laufwerk D: gespeichert, die Festplatte ist aber fast voll. Es
wird eine neue Festplatte als Laufwerk E: im Server eingebaut und diese soll nun für neue Daten
benutzt werden, bereits bestehende Daten sollen aber weiterhin auf Laufwerk D: gespeichert
bleiben und benutzt werden.
Es ist möglich, einen bestehenden Ablageort durch einen anderen abzulösen, ohne dass die Redundanz
erhöht wird. Dieser Vorgang kann mehrfach durchgeführt werden, sodass die abgelösten Ablageorte eine
verkettete Gruppe bilden. Dazu wählt man den alten Ablageort im Datengitter aus, klickt auf
Ablösen und legt im Dialog einen neuen Ablageort (hier auf Laufwerk E:) an. Nach dem Speichern
wird der neue Ablageort anstelle des alten im Datengitter angezeigt. Wenn man sich allerdings die
Einstellungen des neuen Ablageort ansieht (durch Doppelklick ins Datengitter oder Klick auf das
Zahnrad-Icon), sieht man, dass der alte Ablageort dort noch als abgelöster Ablageort angezeigt wird.
Der abgelöste wird nur noch zum Lesen der alten Daten verwendet, neue Daten werden grundsätzlich in
den neuen Ablageort geschrieben.
Löschen von Speichern und Ablageorten
Ein Ablageort kann gelöscht werden, wenn es entweder noch mindestens einen weiteren Ablageort gibt (die Redundanz wird verringert) oder es noch kein Produktiv-Archiv gibt, das diesem Speicher zugewiesen ist (d.h. der Ablageort leer ist). Wenn mindestens eine Migration stattfindet, darf während dieser Zeit kein Ablageort gelöscht werden. Abgelöste Speicher werden als Gruppe betrachtet, d.h. wenn ein Ablageort aus dem Datengitter abgelöste Ablageorte enthält, werden diese gemeinsam mit ihm gelöscht. Diese Regeln sichern zu, dass es in einem Speicher zu jeden Zeitpunkt immer mindestens eine vollständige Kopie aller Daten gibt.
Speicher selbst können nur dann gelöscht werden, wenn alle Ablageorte aus ihnen gelöscht wurden.
Virtuelle Archive
Es gibt nun die Möglichkeit, mehrere bestehende Archive zu einem Archiv zusammenzufassen. Dieses Archiv speichert selbst keine Daten, sondern wird dynamisch generiert ist daher virtuell.
Angenommen, man hat zwei Archive Angebote und Rechnungen, man möchte aber gerne sowohl alle Angebote als auch alle Rechnungen in einem Archiv Kunden gemeinsam betrachten. Wenn man in den virtuellen Archiven auf Neu klickt, gibt man zunächst die üblichen Daten wie z.B. Kurzname und Name ein und wählt dann in der ComboBox Archive die beiden Archive Angebote und Rechnungen aus.
Nun kann es natürlich passieren, dass die beiden Archive nicht die gleichen Spalten konfiguriert haben. In dem virtuellen Archiv muss dann festgelegt werden, welche Spalten man jeweils aus den beiden Archiven anzeigen möchte. Die Spalten im virtuellen Archiv müssen nicht identisch mit den Archiv-Spalten sein, daher muss die Zuordnung manuell durchgeführt werden. Durch die Option “Gleichnamige Felder verwenden” ist es jedoch möglich, Spalten mit identischen Kurznamen automatich als Spalte im virtuellen Archiv hinzuzufügen.
Im virtuellen Archiv können anschließend noch ähnlich wie in normalen Archiven Datenfelder hinzugefügt werden. Zu jedem Datenfeld muss jedoch im Datengitter Zuordnungen festgelegt werden, von welcher Spalten in jedem Archiv die Daten für die virtuelle Spalte benutzt werden sollen. Ein grüner Haken in der Spalte Zuordnungen im Datengitter Datenfelder zeigt an, dass alle Zuordnung korrekt und vollständig ausgefüllt wurden. Erst dann kann gespeichert werden.
SSL-Unterstützung im Webserver
Damit der Webserver über SSL erreicht werden kann, werden signierte SSL-Zertifikate benötigt. In der
settings.ini gibt ssl_certificate den Pfad zu einer Datei an, die das unterschriebene
Zertifikat erhält und ssl_certificate_key den privaten Schlüssel. Sobald beide Optionen eine
gültige Datei enthalten, aktiviert der Server HTTPS.
[General]
ssl_certificate = C:\SSL\mycert.pub
ssl_certificate_key = C:\SSL\mycert.key
ssl_port = 443
ssl_redirect = true
; ...
Wenn von der CA noch sogenannte Intermediate Certificates benötigt werden, müssen diese ebenfalls
in die Datei ssl_certificate kopiert werden.
Standardmäßig wird dafür der Port 443 benutzt, dieser kann aber über den optionalen Parameter
ssl_port angepasst werden.
Wenn der ebenfalls optionale Parameter ssl_redirect auf true gesetzt wird, werden
unverschlüsselte Verbindungen vom Server (auf Port 80 bzw. dem konigurierten Port) zwar weiterhin
akzeptiert, Benutzer werden aber automatisch auf den SSL-Port weitergeleitet.
Terminplanung
Die Terminplanung kann dazu benutzt werden, um Vorgänge zu bestimmten Terminen oder regelmäßig als Wiedervorlage ins Postfach zu legen. Wenn die E-Mail-Benachrichtigung für das Postfach konfiguriert wurde, erhält der Benutzer zu diesem Zeit eine entsprechende Benachrichtigungs-E-Mail.
Termine werden im Reiter Terminplanung in einem Vorgang konfiguriert. Dabei gibt es folgende Optionen:
- Todo
Dieser Text wird als Bemerkung in den Vorgang eingetragen und im Postfach in der Spalte “letzte Bemerkung” angzeigt. Zudem steht dieser Text in der Benachrichtungs-E-Mail.
- Status
Der Status, auf den der Vorgang zum Termin-Zeitpunkt gesetzt werden soll.
- Terminieren für
Der Benutzer, in dessen Postfach der Vorgang zum Termin-Zeitpunkt gelegt werden soll.
- Datum
Der Termin-Zeitpunkt.
- Terminieren für
Ein Zeitraum, der angibt, wie oft der Termin wiederholt werden soll. Damit kann man einen Vorgang z.B. jährlich automatisch wieder ins Postfach geschickt bekommen.
SmartClient
Der SmartClient ist ein Windows-Programm, mit dem Dateien von der Festplatte sehr einfach in den eigenen Eingang ins Archiv kopiert werden können, indem man sie per Drag&Drop in das Fenster des SmartClients zieht. Den SmartClient kann man sich dafür in eine unauffällige Ecke des Bildschirms verschieben und offen halten.
Um sich den SmartClient herunterzuladen, muss man in der Statusleiste des Webclients auf den Button
SmartClient klicken, dabei wird die Datei SmartClient.exe heruntergeladen. Sobald diese Datei
ausgeführt wird, installiert sich der SmartClient in das Verzeichnis %APPDATA%\SmartClient des
Benutzers und startet sich automatisch. Die URL zum Webserver und der Benutzer sind nun bereits
vorkonfiguriert, allerdings muss beim ersten Start das Benutzer-Passwort eingeben werden, das dann
anschließend verschlüsselt in der Datei %APPDATA%\SmartClient\SmartClient.ini abgespeichert
wird.
SmartIndexing
In den Release Notes zur Version 1.2 wurde das SmartIndexing bereits erstmals beschrieben. Die
verfügbaren Funktionen wie z.B. words, dates etc. sind identisch geblieben, allerdings hat
sich die Konfiguration noch einmal verändert und das SmartIndexing ist nun für den Produktiv-Betrieb
freigegeben.
Die ehemals benutzte Konfigurationsdatei smartindexing.ini wird nun nicht mehr verwendet,
stattdessen wird zum Erstellen der Regeln eine XML-Datei verwendet, die mehr Optionen bietet. In der
Datei bin\resources\smartindexing.xml im Installationsverzeichnis werden einige vorkonfigurierte
SmartIndexing-Regeln ausgeliefert. Diese Datei wird bei Updates überschrieben, sodass in zukünftigen
Versionen noch neue Regeln hinzugefügt werden können.
Eigene Regeln können in der Datei smartindexing.xml im config-Verzeichnis abgelegt werden,
diese Datei wird nicht überschrieben. Diese XML-Datei gliedert sich in Sektionen (<section>),
die wiederum die Regeln (<option>) enthalten:
<smartindexing>
<section name="Allgemein">
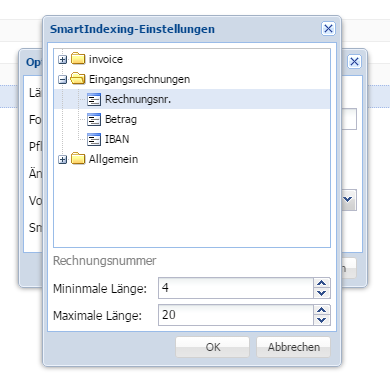
<option id="rechnr" name="Rechnungsnr." description="Rechnungsnummer">
<rule>regex: rex="[0-9]{{{minlen},{maxlen}}}", near=("Rechnungsnr", "Rechnung")</rule>
<param key="minlen" type="integer" description="Minimale Länge">4</param>
<param key="maxlen" type="integer" description="Maximale Länge">20</param>
</option>
</section>
</smartindexing>
Eine <option> benötigt mindestens jeweils eindeutig id und name als Attribut und die
Regel-Definition im Tag <rule>. Zusätzlich kann es noch Parameter geben, die vom Benutzer
verändert werden können. Alle Parameter sind Pflichtfelder, können aber einen Vorgabewert enthalten.
In den erweiterten Optionen von Archiv-Datenfeldern kann für jedes Datenfeld nun eine Regel eingestellt werden:
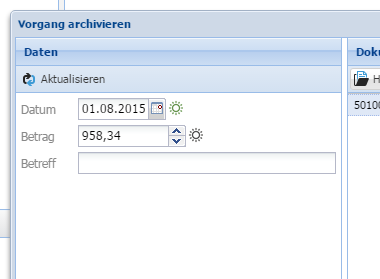
Für alle Datenfelder, in denen SmartIndexing konfiguriert ist, werden nun im Archivieren-Dialog die Felder mit den von SmartIndexing extrahierten Werten vorbelegt. Dies geschieht automatisch, nachdem das erste Dokument für den Vorgang z.B. durch Drag&Drop oder einen Klick auf Archivieren hochgeladen wurde:
SmartIndexing wird aktuell bei folgenenden Dateiformaten unterstützt:
PDF-Dateien, die einfach extrahierbaren Text enthalten.
DOCX-Dateien.
Das SmartIndexing-Ergebnis wird im Archivieren-Dialog über Icons angezeigt:
Ein grünes Sonnen-Icon bedeutet, dass SmartIndexing einen eindeutigen Wert gefunden hat.
Eine graue Sonne bedeutet, dass SmartIndexing mehrere mögliche Werte im Dokument gefunden hat. Mit einem Klick auf das Icon kann man sich alle Werte anzeigen lassen. Sie sind so sortiert, dass das beste Ergebnis ganz oben und das schlechteste ganz unten steht. Das Datenfeld wird immer mit dem obersten Wert vorbelegt.
Wenn es kein Sonnenicon gibt, wurde SmartIndexing für dieses Datenfeld entweder nicht konfiguriert oder es wurde kein passender Wert im Dokument gefunden.
SmartClassify
SmartClassify versucht, neue Dokumente im Eingang anhand statistischer Verfahren automatisch bestehenden Archiven zuzuordnen, indem es Ähnlichkeiten zu bereits archivierten Dokumenten ermittelt.
Damit SmartClassify funktioniert, muss es erst einmal mit den bereits archivierten Vorgängen trainiert werden. Dazu legt man im neuen Bereich Dokumentenarten in der Administrations-Oberfläche beliebig viele Dokumentenarten an, die den Typ von Dokumenten definieren, so kann es z.B. die Typen Rechnungen und Angebote geben. Anschließend muss in den Archiv-Einstellungen jedes Archiv, das ausschließlich Rechnungen enthält, der Dokumentenart Rechnungen zugewiesen werden, und das Ganze analog für Angebote. Daher ist es für SmartClassify wichtig, dass einzelne Archive in diesem Beispiel Rechnungen und Angebote nicht vermischt abspeichern.
Wenn alle Archive den Dokumentenarten zugeordnet sind, muss das Training von SmartClassify über die
pa_ctl.exe durchgeführt werden:
pa_ctl.exe -v smartclassify
Dieser Vorgang kann bei vielen Vorgängen einige Minuten dauern. Anschließend wird SmartClassify im Eingang verwendet:
Sobald ein neues Dokument in den Eingang kopiert wird, wird es im Webclient zunächst mit dem Status Unverarbeitet angezeigt. Der Server überprüft in dieser Zeit, ob das Dokument extrahierbaren Text enthält und führt ggf. eine OCR-Erkennung durch.
Falls aus dem Dokument direkt oder über OCR Text extrahiert werden konnte und es eine trainierte SmartClassify-Datenbank gibt, wird SmartClassify ausgeführt. Anschließend geht das Dokument in den Status Fertig über.
Falls SmartClassify das Dokument einem Archiv zuweisen konnte, wird es vorbelegt und im Datengitter angezeigt. Wenn man nun einen Doppelklick auf das Dokument macht, wird das Archiv im Archivieren-Dialog bereits vorausgewählt und evtl. bereits SmartIndexing ausgeführt.
Migration der Option “Änderbar” in Produktivarchiven
Sobald ein Archiv in den Produktivmodus geschaltet wird, können alle Optionen, die die Revisionssicherheit vermindern könnten, nicht mehr verändert werden. Dazu gehört die Option Änderbar in den erweiterten Einstellung der Datenfelder, die angibt, ob dieser Spaltenwert der Vorgänge auch nachträgtlich noch verändert werden darf.
Durch eine Funktion in der pa_ctl.exe ist es nun möglich, diese Option auch nachträglich noch
anzupassen. Angenommen, im Archiv mit dem Kurznamen rechnungen wurde die Spalte mit dem
Kurznamen eingangsdatum nicht als Änderbar markiert. Das Archiv ist bereits im Produktivmodus,
als auffällt, dass die Daten in dieser Spalte eigentlich doch verändert werden dürfen. Mit folgendem
Befehl kann man die Spalte auf Änderbar setzen:
pa_ctl.exe modify rechnungen chbl D:\mapping.csv eingangsdatum
nochbl hingegen setzt eine veränderbare Spalte auch nicht änderbar.
Dieser Befehl bewirkt, dass die Spalte anschließend nicht mehr in den revisionsicheren Speichern,
sondern nur noch in der Datenbank verwaltet wird. Das bedeutet, dass alle Vorgänge durch eine
Migration neu in die Speicher geschrieben werden und sich die Prüfsumme der Vorgänge verändert.
Daher wird hier in die Datei D:\mapping.csv eine Tabelle geschrieben, die in der ersten Spalte
den alten und in der zweiten Spalte den neuen Hash des Vorgangs hat. Diese Datei kann dazu benutzt
werden, falls z.B. externe Software sich ebenfalls den Hash der einzelnen Vorgänge gemerkt hat.
Vor der Migration der Vorgänge werden noch einmal alle Speicher des Archivs auf Fehler überprüft und nur wenn es gar keine Fehler gibt, wird die Migration durchgeführt. Dennoch wird drigend empfohlen, vor der Migration noch einmal ein Backup sämlicher Speicher und der Datenbank durchzuführen.