SmartTools
SmartSearch
docs365 documents bietet außerdem die Benutzeroberfläche SmartSearch. Die Seite ist responsiv und sowohl für die Verwendung auf Mobilgeräten als auch auf Desktopgeräten optimiert.
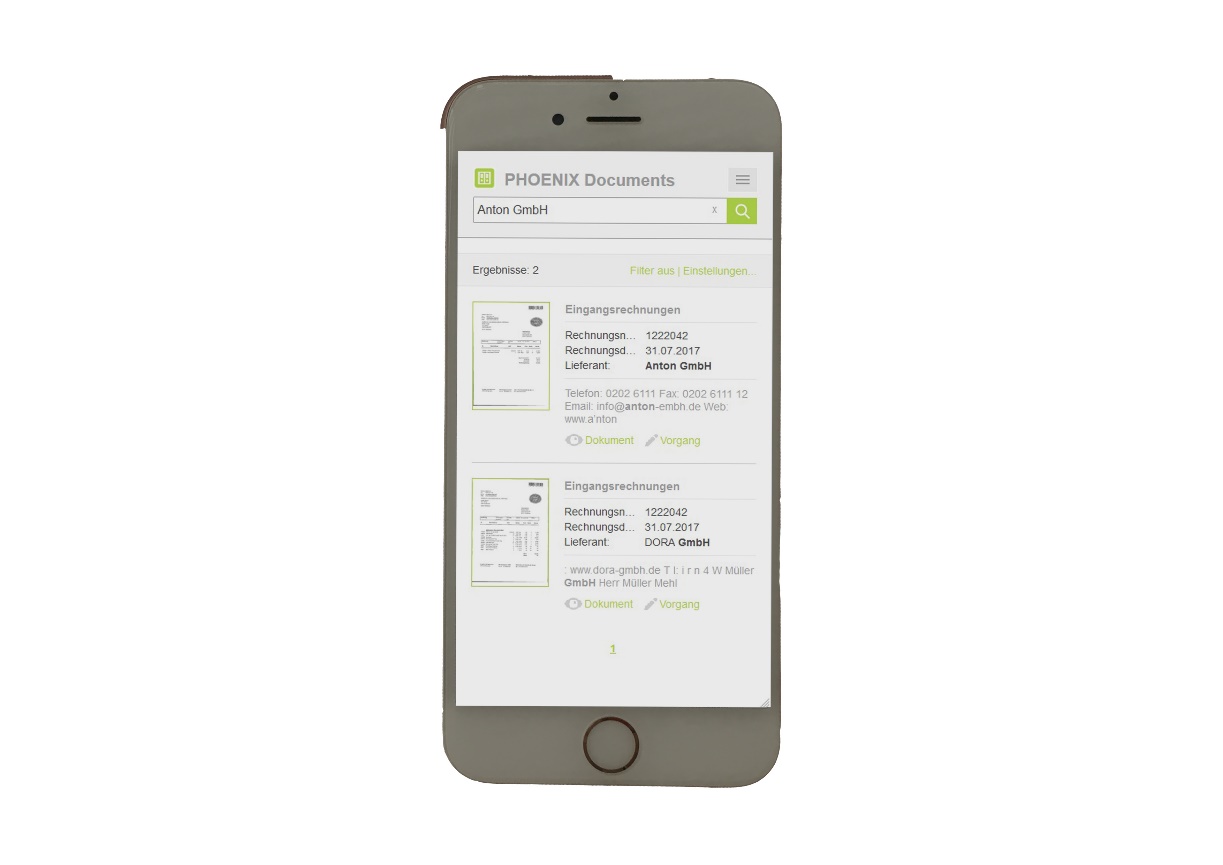
SmartSearch ist eine leistungsfähige Suchmaschine, die speziell für die Anwendung im Dokumentenumfeld entwickelt wurde. Sie nimmt vom Benutzer einen oder mehrere Suchbegriffe entgegen und durchsucht die Index-Daten und Volltexte aller Dokumente in allen Archiven, auf die der angemeldete Benutzer Zugriff hat. Die Ergebnisse der Suche werden dem Benutzer in einer Liste präsentiert.
Näheres zu SmartSearch finden Sie im Handbuch für den Anwender.
Konfiguration der Ergebnisanzeige für Administratoren
Der Dokumententitel in der Ergebnisliste ist konfigurierbar. Außerdem kann eingestellt werden, welche Index-Daten in den Suchergebnissen angezeigt werden. Beide Einstellungen werden in der Administrations-Oberfläche von docs365 documents für jedes Archiv einzeln vorgenommen.
In der Konfiguration eines Archivs findet sich auf dem Reiter Details ein Eingabefeld Titel-Template für SmartSearch. Dieses Feld funktioniert nach dem gleichen Prinzip wie das bereits existierende Feld Postfach-Betreff auf dem Reiter Workflow. Es kann ein beliebiger Text eingegeben werden, in den mit Hilfe von Platzhaltern Index-Daten integriert werden können. Ein Platzhalter besteht aus zwei geschweiften Klammern mit dem Namen des Index-Daten-Feldes dazwischen. Zum Beispiel verwendet das Titel-Template {doctype} für {client} vom {date} die Datenfelder doctype, client und date und würde für ein Dokument mit den Index-Daten doctype=Rechnung, client=Mustermann und date=03.12.2016 den Titel „Rechnung für Mustermann vom 03.12.2016“ anzeigen.
Die Einstellung, welche Index-Daten in der Ergebnisliste angezeigt werden, findet sich in den erweiterten Einstellungen der einzelnen Spalten eines Archivs (Zahnrad-Symbol im Spaltengitter auf dem Reiter Datenfelder).

Am Ende des Dialogs findet sich ein Abschnitt SmartSearch mit der Option In Ergebnisliste anzeigen. Die Einstellung gilt nur für Index-Daten-Felder, die den Suchbegriff nicht enthalten und somit als zusätzliche Information angezeigt werden. Felder, die den Suchbegriff enthalten, werden immer (und mit hervorgehobenem Suchbegriff) angezeigt.
SmartClassify
Bemerkung
SmartClassify steht für docs365 documents Cloud und PHOENIX Archiv nicht zur Verfügung.
SmartClassify versucht, neue Dokumente im Eingang anhand statistischer Verfahren automatisch bestehenden Archiven zuzuordnen, indem es Ähnlichkeiten zu bereits archivierten Dokumenten ermittelt. Das heißt, als Training werden im Archiv ca. 50 Belege archiviert, damit das System lernt, was genau diese Belege ausmacht und worin sie sich unterscheiden oder ähneln.
Dies ist hilfreich, wenn eine Reihe gleichartiger Dokumente im gleichen Archiv landen sollen. Sie können hier einen Arbeitsschritt sparen, denn ohne SmartClassify würden die Dokumente im Eingang erst einmal keinem Archiv zugeordnet.
Sollte SmartClassify Dokumente im Eingang keinem oder dem falschen Archiv zuordnen, können sie in der „Vorgang archivieren“-Maske immer noch richtig zugeordnet werden.
Konfiguration von SmartClassify
Um SmartClassify zu trainieren, sollte jedes Archiv genau eine Dokumentenart haben, die wiederum einen Dokumententyp wie Rechnungen oder Angebote beschreibt. In der Dokumentenart sollten die Trainingsfelder korrekt beschrieben sein. Dann sollte das Archiv schon eine Reihe passender Dokumente enthalten, damit SmartClassify davon „lernen“ kann.
Training mit pa_ctl.exe
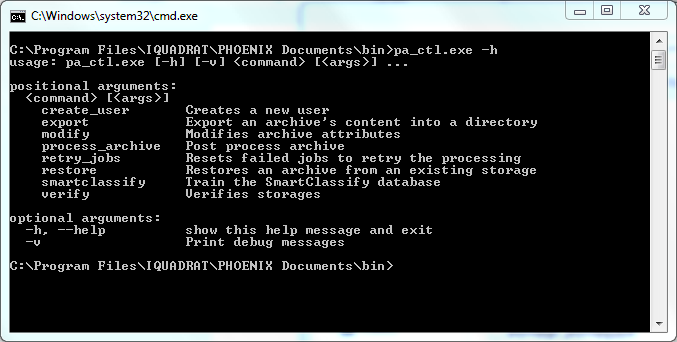
Wenn diese Voraussetzungen erfüllt sind, können Sie aus dem Verzeichnis bin die Datei pa_ctl.exe mit dem Parameter smartclassify ausführen.
Tipp
Wenn Sie mit dem Windows Explorer in das bin-Verzeichnis gehen und während des rechten Mausklicks in eine leere Stelle des Fensters die [Shift]-Taste drücken, haben Sie im Kontextmenü den Eintrag „Eingabeaufforderung hier öffnen“.
Geben Sie am Prompt pa_ctl.exe smartclassify ein. pa_ctl.exe -h zeigt Ihnen alle Optionen.
Das Training kann bei vielen Vorgängen einige Minuten dauern. Anschließend wird SmartClassify im Eingang verwendet:
Sobald ein neues Dokument in den Eingang kopiert wird, wird es im Webclient zunächst mit dem Status Unverarbeitet angezeigt. Der Server überprüft in dieser Zeit, ob das Dokument extrahierbaren Text enthält und führt ggf. eine OCR-Erkennung durch.
Falls aus dem Dokument direkt oder über OCR Text extrahiert werden konnte und es eine trainierte SmartClassify-Datenbank gibt, wird SmartClassify ausgeführt. Anschließend geht das Dokument in den Status Fertig über.
Falls SmartClassify das Dokument einem Archiv zuweisen konnte, wird es vorbelegt und im Datengitter angezeigt. Wenn man nun einen Doppelklick auf das Dokument macht, wird das Archiv im Archivieren-Dialog bereits vorausgewählt und evtl. bereits SmartIndexing ausgeführt.
Um Trainingsdaten wieder zu löschen, können Sie pa_ctl.exe smartclassify delete ausführen.
SmartIndexing
Bemerkung
SmartIndexing steht für PHOENIX Archiv nicht zur Verfügung.
SmartIndexing ermöglicht für hochgeladene PDF-Dokumente (die extrahierbaren Text enthalten müssen), dass bestimmte Datenfelder schon mit Werten vorbelegt werden. Dazu kann man in den Optionen für Datenfelder einen Feldwert aussuchen. Der Feldwert kommt aus der Datei smartindexing.xml im Verzeichnis bin/resources.
Wenn in einer PDF-Datei Metadaten gefunden werden, die zu einem SmartIndex-Eintrag passen, wird neben dem Datenfeld im Archivierungsdialog ein Sonnensymbol angezeigt.
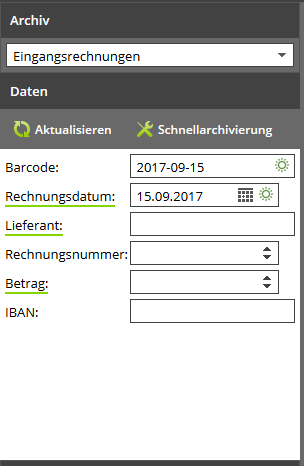
Ein grünes Sonnensymbol bedeutet, dass SmartIndexing einen eindeutigen Wert gefunden hat.
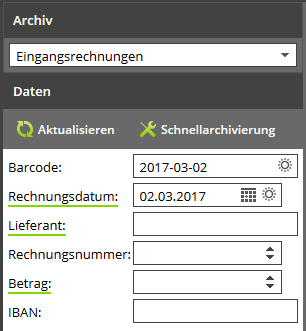
Eine graue Sonne bedeutet, dass SmartIndexing mehrere mögliche Werte im Dokument gefunden hat. Mit einem Klick auf das Icon oder [Ctrl][i] kann man sich alle Werte anzeigen lassen. Sie sind so sortiert, dass das beste Ergebnis ganz oben und das schlechteste ganz unten steht. Das Datenfeld wird immer mit dem obersten Wert vorbelegt.
Wenn es kein Sonnensymbol gibt, wurde SmartIndexing für dieses Datenfeld entweder nicht konfiguriert oder es wurde kein passender Wert im Dokument gefunden.
Eigene Regeln erstellen
Bemerkung
Diese Funktion steht für docs365 documents Cloud nicht zur Verfügung.
Bemerkung
Wenn Sie eigene Regeln erstellen, sollten Sie diese in die smartindeing.xml im config-Verzeichnis schreiben, denn die smartindexing.xml im resources-Verzeichnis wird bei jedem Update überschrieben.
Eigene Regeln können in der Datei smartindexing.xml im config-Verzeichnis abgelegt werden, diese Datei wird bei einem Update nicht überschrieben. Diese XML-Datei gliedert sich in Sektionen (<section>), die wiederum die Regeln (<option>) enthalten:
<smartindexing>
<section name="Allgemein">
<option id="rechnr" name="Rechnungsnr." description="Rechnungsnummer">
<rule>regex: rex="[0-9]{{{minlen},{maxlen}}}", near=("Rechnungsnr", "Rechnung")</rule>
<param key="minlen" type="integer" description="Minimale Länge">4</param>
<param key="maxlen" type="integer" description="Maximale Länge">20</param>
</option>
</section>
</smartindexing>
Eine <option> benötigt mindestens jeweils eindeutig id und name als Attribut und die Regel-Definition im Tag <rule>. Zusätzlich kann es noch Parameter geben, die vom Benutzer verändert werden können. Alle Parameter sind Pflichtfelder, können aber einen Vorgabewert enthalten.
Das Format der SmartIndexing-Funktionen im Tag <rule> sieht folgendermaßen aus:
Der Name der Funktion (z.B. words oder dates), gefolgt von einem Doppelpunkt.
Durch Komma getrennte Parameter der Funktion. Die meisten Parameter müssen mit Namen angegeben werden: name=value
String-Werte benötigten doppelte Anführungszeichen.
Listen sind durch Komma getrennte Werte in einfachen Klammern.
In den erweiterten Optionen von Archiv-Datenfeldern kann für jedes Datenfeld nun eine Regel eingestellt werden.
Für alle Datenfelder, in denen SmartIndexing konfiguriert ist, werden nun im Archivieren-Dialog die Felder mit den von SmartIndexing extrahierten Werten vorbelegt. Dies geschieht automatisch, nachdem das erste Dokument für den Vorgang z.B. durch Drag & Drop oder einen Klick auf Archivieren hochgeladen wurde:
SmartIndexing wird aktuell bei folgenden Dateiformaten unterstützt:
PDF-Dateien, die einfach extrahierbaren Text enthalten.
DOCX-Dateien.
Folgende Funktionen werden aktuell unterstützt:
def now(day=None, month=None, year=None, adddays=0):
"""
Berechnet ein Datum aus dem aktuellen Datum. Kein Bezug zum Text.
day: Ersetzt im aktuellen Datum den Tag durch day
month: Ersetzt im aktuellen Datum den Monat durch month
year: Ersetzt im aktuellen Datum das Jahr durch year
adddays: Addiert zu aktuellen Datum addays Tage
"""
def dates(near=None, near2d=False, past=False, nth=None, fuzzyness=0, ignorecase=True, max_char=None, first_page=None, last_page=None, analyse_filename=False):
"""
Ermittelt die im Text vorkommenden Datumswerte
near: Liste von Worten, in deren Nähe sich ein Datum befinden soll
near2d: Falls True, wird der Abstand zu einm near-Wort als euklidischer Abstand berechnet.
past: Nehme nur Daten auf, die in der Vergangenheit liegen
nth: Liefere nur das nte Datum zurück
fuzzyness: Größe der fuzzyness
ignorecase: Ignoriere Groß/Kleinschreibung
max_char: Maximale Anzahl der durchsuchten Zeichen
first_page: Erste Seite (Nummerierung beginnt mit Seite 1) des zu durchsuchenden Textes (Seitentrennner ist Form feed)
last_page: Letzte Seite des zu durchsuchenden Textes (Seitentrennner ist Form feed)
analyse_filename: Falls True, wird als Text der filename verwendet, ansonsten der content
"""
def decimals(near=None, near2d=False, nth=None, fuzzyness=0, ignorecase=True, max_char=None, first_page=None, last_page=None, analyse_filename=False):
"""
Ermittelt die im Text vorkommenden Dezimalzahlen mit zwei NK-Stellen
near: Liste von Worten, in deren Nähe sich ein Datum befinden soll
near2d: Falls True, wird der Abstand zu einm near-Wort als euklidischer Abstand berechnet.
nth: Liefere nur die nte Dezimalzahl zurück
fuzzyness: Größe der fuzzyness
ignorecase: Ignoriere Groß/Kleinschreibung
max_char: Maximale Anzahl der durchsuchten Zeichen
first_page: Erste Seite (Nummerierung beginnt mit Seite 1) des zu durchsuchenden Textes (Seitentrennner ist Form feed)
last_page: Letzte Seite des zu durchsuchenden Textes (Seitentrennner ist Form feed)
analyse_filename: Falls True, wird als Text der filename verwendet, ansonsten der content
"""
def words(lookups, near=None, near2d=False, nth=None, fuzzyness=0, ignorecase=True, max_char=None, first_page=None, last_page=None, analyse_filename=False):
"""
Ermittelt die im Text vorkommenden Worte aus der Lookupliste
lookups: Liste von Worten, nach deren Auftreten im Text gesucht wird
near: Liste von Worten, in deren Nähe sich ein Datum befinden soll
near2d: Falls True, wird der Abstand zu einm near-Wort als euklidischer Abstand berechnet.
nth: Liefere nur das nte Wort zurück
fuzzyness: Größe der fuzzyness
ignorecase: Ignoriere Groß/Kleinschreibung
max_char: Maximale Anzahl der durchsuchten Zeichen
first_page: Erste Seite (Nummerierung beginnt mit Seite 1) des zu durchsuchenden Textes (Seitentrennner ist Form feed)
last_page: Letzte Seite des zu durchsuchenden Textes (Seitentrennner ist Form feed)
analyse_filename: Falls True, wird als Text der filename verwendet, ansonsten der content
"""
def regex(rex, group=0, subrex=None, replacement=None, nth=None, near=None, near2d=False, fuzzyness=0, ignorecase=True, max_char=None, first_page=None, last_page=None, analyse_filename=False):
"""
Ermittelt die im Text vorkommenden Worte aus der Lookupliste
rex: Regulärer Ausdruck, nach dem im Text gesucht wird
group: Welche Gruppe des Treffers verwendet wird. Falls = 0, wird der gesamte Treffer verwendet
subrex: Falls ein Treffer noch bearbeitet werden soll, enthält subrex den dafür notwendigen reg. Ausdruck
replacement: Ersetzung für den gefunden Teil (subrex) des Treffers
near: Liste von Worten, in deren Nähe sich ein Datum befinden soll
near2d: Falls True, wird der Abstand zu einm near-Wort als euklidischer Abstand berechnet.
nth: Liefere nur den nten Treffer zurück
fuzzyness: Größe der fuzzyness
ignorecase: Ignoriere Groß/Kleinschreibung
max_char: Maximale Anzahl der durchsuchten Zeichen
first_page: Erste Seite (Nummerierung beginnt mit Seite 1) des zu durchsuchenden Textes (Seitentrennner ist Form feed)
last_page: Letzte Seite des zu durchsuchenden Textes (Seitentrennner ist Form feed)
analyse_filename: Falls True, wird als Text der filename verwendet, ansonsten der content
"""
def slice(start=None, end=None, first_page=None, last_page=None, analyse_filename=False):
"""
Ermittelt text[start:end] als python-slice. Gut verwendbar für Dateinamen.
start: Startwert des slice
end: Endwert des slice
first_page: Erste Seite (Nummerierung beginnt mit Seite 1) des zu durchsuchenden Textes (Seitentrennner ist Form feed)
last_page: Letzte Seite des zu durchsuchenden Textes (Seitentrennner ist Form feed)
analyse_filename: Falls True, wird als Text der filename verwendet, ansonsten der content
"""
def part(n, delemiter=None, max_char=None, first_page=None, last_page=None, analyse_filename=False):
"""
Ermittelt den nten Teil der Split-Liste. Gut verwendbar für Dateinamen.
n: n
delemiter: Trenner für die Split-Liste
max_char: Maximale Anzahl der durchsuchten Zeichen
first_page: Erste Seite (Nummerierung beginnt mit Seite 1) des zu durchsuchenden Textes (Seitentrennner ist Form feed)
last_page: Letzte Seite des zu durchsuchenden Textes (Seitentrennner ist Form feed)
analyse_filename: Falls True, wird als Text der filename verwendet, ansonsten der content
"""
In Import-Services kann bei den Funktionen run_smartclassify und run_smartindexing nun über den Parameter ocr=True die OCR-Verarbeitung für PDFs und Bilder aktiviert werden. Damit funktionieren SmartIndexing und SmartClassify beim Import jetzt auch mit Dokumenten, die nicht bereits extrahierbaren Text enthalten.
SmartIndexing-Regeln
Für Rechnungen gibt es folgende mitgelieferte SmartIndexing-Regeln mit Vorschlägen aus Datentabellen:
IBANs werden validiert, d. h. es werden nur noch gültige IBANs vorgeschlagen.
Die Trefferquote für Beträge wie Bruttobetrag, Nettobetrag und Steuerbetrag ist mit einem neuen Verfahren deutlich höher.
Die beiden Regeln Lieferant und Kreditor ermitteln Werte durch Nachschlagen in einer Datentabelle anhand der IBAN. Dafür wird automatisch eine erste Datentabelle mit dem Namen Lieferanten eingerichtet, die die drei Spalten IBAN, Name und Fibu-Konto enthält und von den beiden SmartIndexing-Regeln Lieferant und Kreditor verwendet wird. Dazu muss man diese Datentabelle zunächst mit Daten aus einer CSV-Datei füllen, anschließend arbeiten diese Regeln folgendermaßen:
Wenn die SmartIndexing-Regel Lieferant ausgewählt wird, wird zunächst eine IBAN aus dem Dokument extrahiert. Falls das erfolgreich ist, wird in der Datentabelle nachgesehen, welcher Name zu dieser IBAN gehört. Falls ein Wert gefunden ist, wird dieser Name von SmartIndexing zurückgegeben.
Die Regel Kreditor funktioniert identisch, nur dass die Datentabellen-Spalte Fibu-Konto zu der gefundenen IBAN zurückgegeben wird.
In der SmartIndexing-Regel „USt-IdNr“ ist es nun möglich, eine „eigene USt-IdNr“ zu hinterlegen, damit diese beim Ausführen der SmartIndexing-Regel ignoriert werden kann.
SmartIndexing-Services
SmartIndexing kann durch eigene, in Python programmierte Regeln erweitert werden, womit auch deutliche komplexe Informationen aus Dokumenten extrahiert und dem Benutzer vorgeschlagen werden.
Die Details der Indexing-Services werden in einer separaten Dokumentation beschrieben.